Architecture: The Underrated Moat
One of the most undervalued moats in technology is the infrastructure that technology is distributed through. For new ventures, finding product market fit often requires being able to iterate a few times to find the exact offering that resonates with the most customers. You can achieve faster iteration cycles through two means: more engineers, or a well-designed infrastructure. The ability to iterate and release faster than competitors will give a company a higher probability of success. More so than one that may have had an innovative technology solution to start. Even the best of leads can erode, and a good infrastructure can either maintain that lead or cripple it.
The challenge with building a good infrastructure is supporting the right infrastructure for the current problem/team and being able to transition your infrastructure effectively when future needs or challenges arise. The most popular architecture at time of writing is a microservice architecture. The move from virtual machines to containerization and the rise of Kubernetes have greatly reduced the barriers for engineering teams to utilize microservices. Over the last decade we saw several companies document their grueling transitions from monoliths to microservices and the success it brought about. As a result, every company saw being on microservices as the right infrastructure. But is it always? In this article I walk through the pros and cons of monoliths and microservices and make a case that both can be used effectively. Starting with the right architecture for your team and your projects roadmap is no easy decision. But, with good planning and foresight, starting with monolith might be the best way to stay ahead of your competition.
System Designs
The Monolith

This is a system design where all the code is in a single code base often supported by a single database, or single database instances per data function – i.e SQL for relational data, Redis for cached data, IndexDBs for search data, etc… In most modern teams, when we talk of monoliths we are typically describing the backend architecture - almost everyone has or should have abandoned the MVC architecture by now and be utilizing server agnostic clients. The main advantage of the monolith is that it generally does everything well but not exceptionally well. Their biggest drawback is that they represent a single point of failure and the things they do generally well, start to preform less efficiently as the size of the team and the code base scale. Some examples (though not all) would be:
Slow deployments due to deploying entire code base each time.
Inefficient resource utilization, again due to entire code base in each container
Merge queues due to too many engineers working in single repository.
Poorly delineated separation of concerns for code.
Difficult to update shared libraries across the code base.
Monoliths are generally seen as poor preforming architectures, but if designed properly can out preform microservices that are not architected properly. Issues such as poor code quality, code regressions, high application error rates ..etc are not symptoms of monoliths but issues that arise as result of lack of proper standards and poor enforcement of quality controls in a code base– problems microservices are also not immune to. Coding is a social practice and requires both a mixture of programmed rules (linters and compiler rules) and social rules (how to structure files, functions, and imports) to assure quality. In smaller codes bases and teams, the monolith efficiencies outperform its inefficiencies. It’s just that in a large organizations or large code bases the issues highlighted earlier really start to dominate exponentially. However its not important not to ignore the benefits monoliths provide,for example:
High observability because everyone can see every part of the code
Uniform security and development standards because the entire code base is governed by the same practices.
Single version controlled API
Less infrastructure overhead
Stronger End to End testing.
Simplified database transaction management

There are also still ways to make monoliths behave like microservices. One technique that can be utilized within monoliths to gain the benefits of decentralized code in a centralized code base is the utilization of code isolated modules under the practice of domain drive design. What this means is that these modules reside in the same environment and runtime, but they can’t borrow code from each other and operate independently. There are ways to share code between modules, but a good way to maintain that separation is by preventing modules from directly importing code from other other modules. These modules would need to communicate with each other the same way microservices do, either through common apis utilizing rest or gRPC. By creating code isolated modules in a monolithic code base, teams can work on their scope only, while still benefiting from high observability, consistent standards, shared security, and end to end testing. Nest.js is an example of a loosely opinionated Node.Js framework that can guide engineers to this pattern – similarly Django for python.
Modules can also be deployed as a single monolith or individually depending on how CI/CD is configured. Furthermore, if a module requires being isolated as a microservice it can be removed effortlessly since it has fundamentally behaved as a microservice the entire time. All would really have to do is copy that module out into its own runtime and deployable service built on the same environment its been running in the whole team. This for the most part, just a small copy paste effort of code if setup well from the beginning. Which leads to the next architecture discussion.
Microservices

Microservices rose in popularity largely due to containerization and Kubernetes. Kubernetes combined with infrastructure as code has caused microservice architectures to become the dominate design pattern for modern architectures. The main advantages of microservices are:
No single point of failure
Strict enforcement of code isolated domains
Resource efficient scaling
Enabling multiple programming languages to be used in an architecture design.
Easier to update.
These benefits come at a cost that is mostly tied to engineering discipline. Microservices introduce more moving pieces and so without good habits being already developed in the team microservices can become a burden quickly and slow velocity after an initial rise. Some of these habits can be automated by a good platform or site reliability team – though the complexity of doing this well can be a never-ending set of trade off decisions. Some of the challenges microservices can introduce into an organization are:
Decreased observability since other teams lack the ability to see each other’s code
Inconsistent application of standards and best practices
Interservice communication failure (one service updates its API causing breaking changes across other services)
Multiple API version management (each service must manage and support its clients which can be other services)
Infrastructure overhead and deployment complexity.
Complex transaction management.
Microservices will always be superior architecture design over monoliths. However, a team often rushes into microservices as a means of aiming to solve a few major short-term issues. They often forget to prepare for the other fundamentals required to manage a healthy infrastructure. The main areas that are often overlooked are testing infrastructures, interservice communication, and database schema management. The benefits of code isolation and service autonomy can be brought down by operational regressions introduced from the lack of proper “scaffolding” surrounding the architecture. Monoliths allow you to be “lazier” for lack of a better description because problems can be patched quickly. Since microservices have more moving parts they require more planning and consideration to avoid regressions and even to fix them properly. An entire alternate document can be written to discuss the supporting architecture required for a microservice and won’t be discussed here.
Event Driven

Event driven architectures are rarely considered the primary architecture design for a system. They are more often a supportive design pattern to an existing architecture that handles the core businesses logic of the application. These architectures are typically characterized by a publisher/subscriber model where messages are “published” to a stream and then various consumers (like specific services in a microservice architecture) would subscribe to those streams and either pull or have messages pushed to them where they are processed. How these messages are published or consumed is agnostic to the architecture – they can come and go to various sources.
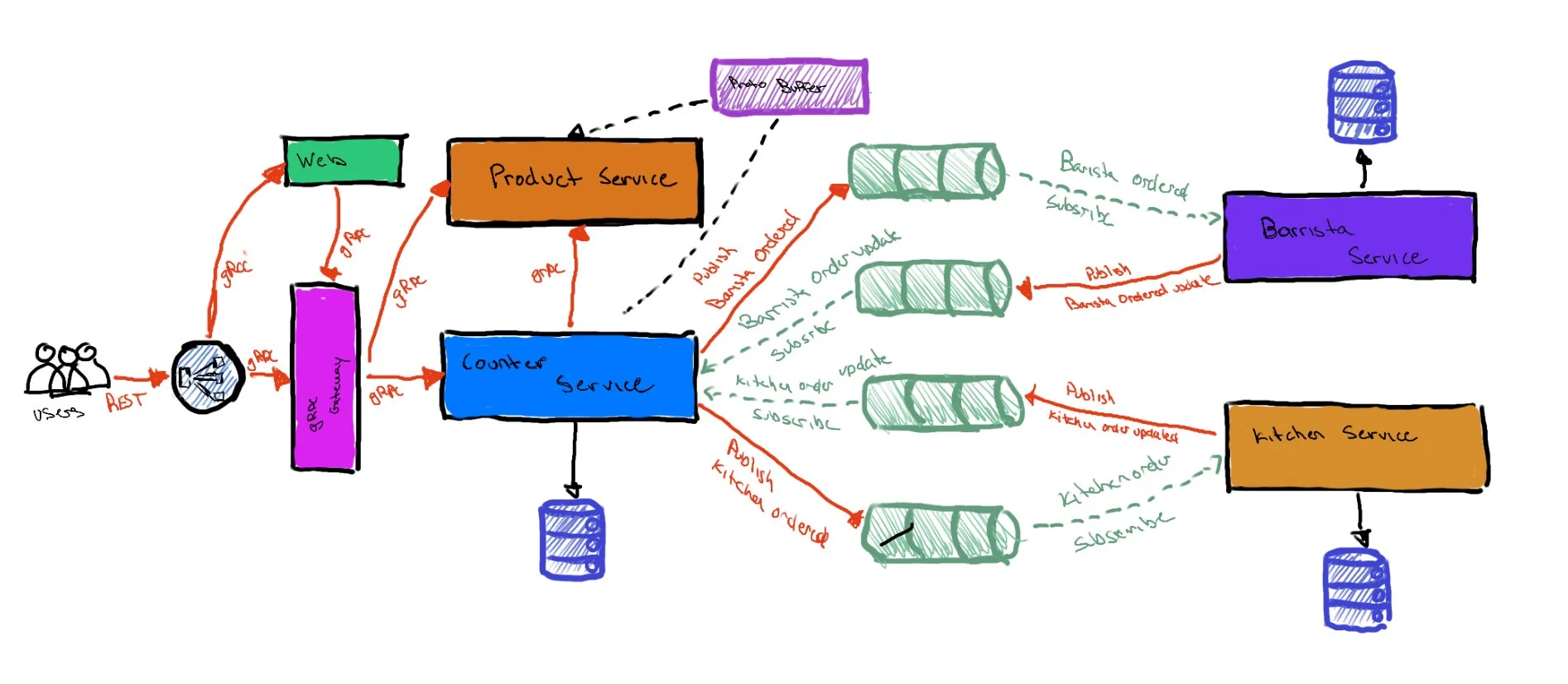
In an Event Driven Architecture an event bus is primarily used for reliably moving small packets of data (messages) around the system. Tools like RabbitMQ, Kafka, GCP Pub/Sub and AWS SQS/SNS are common examples of varying integration complexity. It does not execute any operations on the message. It just ensures it is moved along to all the places it needs to go and records successful receipt of messages signified by “acks” (acknowledgments from the subscriber). For this reason these architectures are used in real time applications, applications with lots of asynchronous logic, or to add resiliency to an existing applications architecture by ensuring cross service messages or messages to the services themselves are not lost/dropped and can be replayed if errors occur (if endpoints are idempotent).
Serverless
I’m not going to devote much time to serverless since it’s an architecture pattern that should have never been utilized for an organizations core business logic. Serverless functions are functions that only run when invoked. The main advantage of serverless architectures is that you are not allocating compute resources all the time, only when required. With serverless architectures you essentially have an active runtime that is shared by atomic functions that are live for short execution cycles. You can either setup your own serverless infrastructure or use a provided service like AWS lambda. The idea is that these functions can scale significantly faster than microservices because they can be increasingly allocated to available memory in a run time. These functions are also atomic and don’t share an environment (just the runtime) with other functions allowing them to be updated without impacting any other operation – except for poor importing habits that makes the functions less atomic.
When used as part of your core business logic you typically end up with a serverless function repeatedly invoked such that it behaves more like a function continuously running on a dedicaated server. This is not only costly with regard to AWS Lambda, but also slow since this functions need to be mounted and unmounted from memory each time they are called. If they are called with such frequeency that is always available in memory.. then is no longer operating as serverless functions are intended to operate. Serverless functions, like event based systems are best utilized as supporting infrastructure to a core monolith or microservice architecture. If part of an organizations business logic requires code to be invoked with extreme irregularity, or in short scheduled and distant intervals, or to curry messages infrequently in an event-based system – serverless functions are a great solution. The only exception to using serverless as the dedicated infrastructure is if you plan to offer your services in a manner where you expect others to execute atomic functions on your infrastructures runtimes. This is more of business decision, what type of company you are, versus how you should build your architecture. Think of serverless functions as tools, not architectures.
Many organizations made the decision to build their entire infrastructure on serverless managed services (like AWS Lambda). The downside is many of the same downsides of microservices, however the major one is cost. Serverless functions on AWS cost more per compute runtime compared to dedicated services. There is an inevitable inflection point where the cost of serverless architecture will cost significantly more than a dedicated server architecture. Unless you are the one owning and operating the server and runtime the functions are invoked on. Also, the fragmentation of the functions can also significantly reduce the observability of the system. This is not to say, don’t use severless, there are just more constrained use cases for it than would appear in the public programming zietgiest.
Which infrastructure to choose?
This a highly opinionated discussion so I’ll provide some of my personal experiences to start. Whenever I start a new project, I typically start with a monolith or a small microservice architecture (typically with three services, api-service, identity-service, and migration-service where the api-service is setup like a modular monolith) in a monorepo structure. The main reason being that in small teams the more observability and the closer the code is together the faster you can move. Utilizing a monolith means that you’re not waiting for some other teams service to deploy or some package to be published. Additionally, utilizing a monorepo means that both the frontend code and backend code is also in one place along with all the configuration files needed for managing all environments including deployments. For many this sounds awful and cluttered but with proper folder segmentation in your repository it should be easier than having 5 different repositories to manage. This structure scales well to about 20-30 engineers and if the team has good git flow practices in places (a discussion for another post) can easily scale to 100 engineers. The biggest challenge with this starting foundation is just pull request noise (too many PR’s open on one repository at a time).
So how do you plan for the point where you need to break out of the monolith? Here is a link to another article that discusss this, but to keep it brief, its important to put some foundational rules in place before everyone starts coding. As said before, programming is as much a social and collaborative exercise as it is an individual robotic output of instructions. Some of these rules are very difficult to write linters or compiler rules for, often they just need to be inforced socially - on PR’s. This is where engineering discipline matters because following the right team rules and enforcing them on PR’s ensures the ability to easily decouple in the future (admittedly this is the most difficult challenge with regard to scaling code bases). Here is an example for how I instruct code to be arranged in a module. This is a start of foundational rules I often modify depending on the team, the current state of the project, and the skill level of everyone involved.
```
module \
controller.ts \
validators.ts \
service.ts \
repo.ts \
jobs.ts \
types.ts
```
####Controllers###
Controllers are responsible for routing traffic through the module. They define the endpoints and methods used to call them
####Validators####
This file contains the schema validators for the endpoints. If requests queries or bodies fail to pass the schema they will be rejected before reaching the controllers handlers
####Services####
Services are the predominant business logic layer of the module. If this file gets large consider turning into _services_ folder and breaking up the service file into seperate service files in the folder.
####Jobs####
If a Module needs to run any cron jobs they are defined here and imported into the cron-job-scheduler file int he root of the repository
####Repo####
This file represents the Data Access Layer of the module. It inherits its ORM (Knex) from the db-utils folder. The Service uses a lazy transcation manager pattern. This means that a database transaction is initiated at the start of a request being received by the server. Transcations are then added throughout the lifecycle of a request. When the server is about to return a response the transactions are all committed at once. This means that if a request fails, all transactions in that request fail at the same time - so nothing is written to the database. See http-utils package to read code for how this is managed.And here are some rules and examples for how I instruct where code should be placed in a repository.
The reason for these rules is that if someone looks at a file they have an immediate understanding of what it should be doing, what connects to it and what it likely connects to. Furthermore it also can give you a quick idea of the scope of how many other files a change in a file may affect. These little basics go a long way in preventing regressions and over relying on unit testing (I’m also not a big fan of unit testing and I’ll explain why in another post). If these files and folders are arranged correctly - moving them to independent services should be an easy copy and paste effort.
Its important to know as your project gets bigger more specialized teams need to emerge to manage it; platform teams and Site reliabiltity teams. This is just like how a mansion requires a staff to maintian and a small home doesn’t. Transitioning to microservices before these teams are setup properly will subvert the architectures benefits and possibly slow your team down more than a monolith.
If you want to learn how to migrate to microservices from a monolith -> read more here.